
Nội dung
- 1. Hệ thống khuyến nghị và phương pháp Lọc cộng tác
- 2. Kiến trúc AutoRec
- 3. Thực nghiệm với bộ dữ liệu MovieLens
- 4. Tổng kết
- 5. Tham khảo
1. Hệ thống khuyến nghị và phương pháp Lọc cộng tác
Hệ thống khuyến nghị (recommendation system), là hệ thống giúp đưa ra khuyến nghị những sản phẩm thích hợp nhất đối với những người dùng cụ thể nào đó. Thường quá trình khuyến nghị này phụ thuộc vào nhiều yếu tố, ví dụ như sản phẩm nào họ đã từng mua, những sản phẩm nào họ đã tương tác (nút like), nhạc nào họ đã từng nghe, món nào họ đã từng ăn hoặc dựa trên những người họ quen biết trên nền tảng điện tử đó, hoặc dựa trên những người dùng có hành vi tương đối giống họ.
Vâng, là dựa vào những người dùng có hành vi tương đối giống họ, đây là giải thích ngắn gọn cho phương pháp lọc cộng tác. Phương pháp lọc cộng tác (collaborative filtering) dùng dữ liệu từ những người dùng có hành vi tương đối giống họ (đánh giá dựa trên khoảng cách được tính từ một số yếu tố như có phải bạn bè hay không, các bộ phim đã yêu thích, thể loại đã xem, yêu thích, mức đánh giá …) để đưa ra khuyến nghị cho người dùng đó tương tự như những người dùng này.
Có thể bắt gặp nhiều phương pháp lọc cộng tác khác nhau khi tìm từ khoá collaborative filtering, ví dụ như Neighborhood-based, Matrix Factorization (MF), Restricted Bolzmann Machine-based (RBM-based), …, vì các phương pháp này đã được thử nghiệm từ lâu. Nhưng phương pháp mà tôi trình bày trong bài viết này có lẽ vẫn còn mới hơn các phương pháp kể trên nên có thể tìm kiếm sẽ không thấy được, paper gốc của phương pháp này được công bố vào 5/2015.
2. Kiến trúc AutoRec
Trong paper gốc của AutoRec [1], tác giả sử dụng và chỉnh sửa lại dạng mạng nơ-ron liên kết tự động (auto-associative neural network) Autoencoder. Tác giả sử dụng Autoencoder vì sự thành công của mạng nơ-ron sâu (deep neural network) vào khoảng thời gian tác giả nghiên cứu kiến trúc này. Tác giả tin rằng, AutoRec sẽ có điểm lợi hơn các phương pháp Matrix Factorization và RBM-based về thời gian tính toán và biểu diễn dữ liệu.
Đối với một hệ thống điện tử, ta sẽ có $m$ user và $n$ item và trong ngữ cảnh CF, ta sẽ có thêm một ma trận đánh giá (user $u$ đánh giá item $i$) quan sát một phần (không đầy, sẽ có những chỗ là giá trị $0$) user-item $R \in \mathbb{R}^{m \times n}$. Trong rating-based, mỗi user $u \in U = \{1 \cdots m\}$ được biểu diễn bởi một vector rating quan sát một phần $\mathrm{r}^{(u)} = (R_{u1}, \cdots, R_{un}) \in \mathbb{R}^n$. Còn trong user-based, mỗi item $i \in I = \{1 \cdots n\}$ được biểu diễn bởi một vector rating quan sát một phần $\mathrm{r}^{(i)} = (R_{1i}, \cdots, R_{mi}) \in \mathbb{R}^m$. Mục tiêu của việc sử dụng Autoencoder trong rating-based (hoặc item-based) là nhận một vector quan sát một phần $\mathrm{r}^{(i)}$ (hoặc $\mathrm{r}^{(u)}$), chiếu nó xuống không gian ẩn có có số chiều thấp hơn, và tái tạo lại $\mathrm{r}^{(i)}$ (hoặc $\mathrm{r}^{(u)}$) tương ứng để dự đoán những rating bị thiếu (những vị trí mà giá trị hiện tại là $0$ hoặc rỗng) cho mục đích khuyến nghị (từ rating dự đoán ta có thể sắp xếp lại các sản phẩm phù hợp để đưa cho người dùng).
Cụ thể về mặt toán học, ta có một tập $\mathrm{S} \in \mathbb{R}^d$ gồm các vector và một giá trị $k \in \mathbb{N}_{+}$, Autoencoder sẽ giải:
\[\underset{\theta}{\mathrm{min}} \sum_{\mathrm{r} \in \mathrm{S}}||\mathrm{r} - h(\mathrm{r}; \theta)||^2_{2}\]trong đó $h(\mathrm{r}; \theta)$ là giá trị rating được tái tạo của $\mathrm{r} \in \mathbb{R}^d$,
\[h(\mathrm{r}; \theta) = f(\mathrm{W} \cdot g(\mathrm{V}\mathrm{r}+\mathrm{\mu}) + \mathrm{b})\]với các activation function $f(\cdot)$, $g(\cdot)$. Và bộ các tham số của mô hình $\theta = \{\mathrm{W}, \mathrm{V}, \mathrm{r}, \mathrm{b}\}$, có kích cỡ lần lượt là $\mathrm{W} \in \mathbb{R}^{d\times k}$, $\mathrm{V} \in \mathbb{R}^{k\times d}$ và các bias $\mathrm{\mu} \in \mathbb{R}^k$, $\mathrm{b} \in \mathbb{R}^d$. Hàm mục tiêu của Autoencoder ở trên là hàm mục tiêu điển hình của mạng nơ-ron tự liên kết, một lớp ẩn có $k$ chiều, và bộ tham số $\theta$ sẽ được học thông qua back-propagation.
Với AutoRec, tác giả sử dụng lại công thức của hàm mục tiêu Autoencoder phía trên, với 2 thay đổi:
- Chỉ cập nhật những trọng số tương ứng với những quan sát đã có, bằng cách nhân với mask trong quá trình huấn luyện, ta sẽ loại bỏ cập nhật được những quan sát chưa có.
- Chỉnh hoá các tham số của mô hình để tránh việc Overfit xảy ra.
Vì thế, khi áp dụng hàm mục tiêu của Autoencoder với 2 thay đổi trên vào bộ vector rating của Item-based (gọi là I-AutoRec) $\{\mathrm{r}^{(i)}\}^n_{i=1}$ và tham số chỉnh hoá $\lambda > 0$ bất kỳ, ta sẽ có hàm mục tiêu của AutoRec:
\[\underset{\theta}{\mathrm{min}} \sum_{i=1}^n||\mathrm{r^{(i)}} - h(\mathrm{r^{(i)}}; \theta)||^2_{\mathcal{O}} + \dfrac{\lambda}{2}\cdot (||\mathrm{W}||^{2}_{F} + ||\mathrm{V}||^{2}_{F})\]trong đó, kí hiệu \(\|\cdot\|^{2}_{\mathcal{O}}\) thể hiện rằng chỉ xem xét những giá trị đã quan sát được (đã rating). Với User-based (gọi là U-AutoRec), ta áp dụng tương tự đối với tập vector rating $\{\mathrm{r}^{(u)}\}^m_{u=1}$. Tổng quan lại, I-AutoRec sẽ yêu cầu ước lượng $2mk + m + k$ tham số tất cả. Khi đã học được tham số $\hat{\theta}$, dự đoán rating của user $u$ dành cho item $i$ là:
\[\mathrm{R}^{ui} = (h(\mathrm{r}^{(i))}; \hat{\theta}))_{u}\] 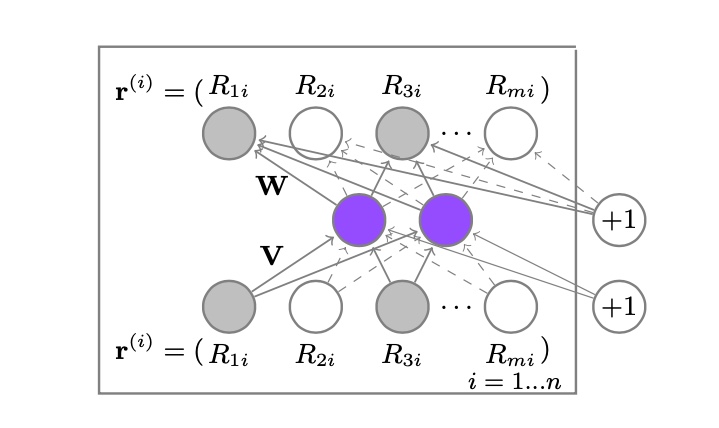 Hình 1. Cấu trúc của Item-based AutoRec, các node màu xám thể hiện rating đã có, màu trắng thể hiện không có rating và là giá trị cần dự đoán.
Hình 1. Cấu trúc của Item-based AutoRec, các node màu xám thể hiện rating đã có, màu trắng thể hiện không có rating và là giá trị cần dự đoán.
Ở trong nghiên cứu, tác giả đề cập đến việc sử dụng các loại activation function khác nhau cho $f(\cdot)$ và $g(\cdot)$, bảng dưới đây đánh giá RMSE của các kết hợp (càng thấp càng tốt). Trong đó Identity là không có hàm kích hoạt, còn Sigmoid được định nghĩa ở đây.
| $f(\cdot)$ | $g(\cdot)$ | RMSE |
|---|---|---|
| Identity | Identity | $0.872$ |
| Sigmoid | Identity | $0.852$ |
| Identity | Sigmoid | $\textbf{0.831}$ |
| Sigmoid | Sigmoid | $0.836$ |
Trong paper gốc, tác giả đề cập rằng AutoRec rất khác so với các mô hình dành cho CF lúc đó. Cụ thể, khi so sánh AutoRec với RBM-CF, ta có:
- RBM-CF là dạng mô hình tổng hợp xác suất (generative, probabilistic model) dựa trên RBM. Còn AutoRec là mô hình phân biệt (discriminative model) dựa trên Autoencoder.
- RBM-CF ước lượng các tham số bằng tối đa hoá log khả năng (maximizing log likelihood), còn AutoRec trực tiếp minimize RMSE, mà đây cũng là cách đánh giá hiệu suất kinh điển trong bài toán dự đoán rating.
- RBM-CF huấn luyện bằng contrastive divergence, còn AutoRec sử dụng gradient-based backpropagation, mà nhanh hơn nhiều so với RBM-CF.
- RBM-CF chỉ sử dụng được cho rating dạng rời rạc. Còn AutoRec dùng cho rating dạng liên tục. Với $r$ rating, RBM-CF phải tốn $nkr$ hoặc $mkr$ tham số, trong khi đó AutoRec không quan tâm đến số lượng $r$ nên dùng ít bộ nhớ hơn và khó overfit hơn.
Còn khi AutoRec so sánh với Matrix Factorization thì:
- MF nhúng cả item và user vào không gian ẩn, còn I-AutoRec chỉ nhúng item (U-AutoRec chỉ nhúng user), nên mô hình sẽ nhẹ hơn.
- MF học một cách biểu diễn ẩn tuyến tính (linear latent representation), còn AutoRec có thể biểu diễn dữ liệu ẩn theo dạng phi tuyến (nonlinear latent representation) thông qua hàm kích hoạt $g(\cdot)$, mà sẽ tạo được sự tổng quát hoá dữ liệu tốt hơn nhiều.
Trong phần sau, chúng ta sẽ đi thực nghiệm AutoRec bằng Pytorch trên bộ dữ liệu Movielens.
3. Thực nghiệm với bộ dữ liệu Movielens
Bộ dữ liệu Movielens là sự lựa chọn số một trong việc đánh giá các hệ thống khuyến nghị vì lượng dữ liệu dồi dào mà nó có. Trong bài viết này, ta sẽ sử dụng bộ Movielens 1 triệu rating để thực nghiệm. Bạn đọc có thể tải về ở đường dẫn sau
Theo như ở phần 2 phía trên, ta đề cập đến việc tác giả đưa ra 2 sự thay đổi đối với Autoencoder ban đầu để biến nó thành AutoRec. Ta thấy ở thay đổi thứ 2, mục tiêu của tác giả là tránh overfit cho model và việc tác giả làm đó là sửa đổi hàm loss và phạt các trọng số, thường gọi là chỉnh hóa. Ngoài ra ta biết trong Deep Learning, để tránh overfit cho model, người ta thường sử dụng Dropout với một tỉ lệ hợp lý. Nên trong phần này, tôi sẽ thực nghiệm trên 2 kiến trúc: một là implement lại công thức của tác giả, hai là implement lại theo style của deep learning, thay chỉnh hóa phạt trọng số bằng dropout, kết quả của 2 cách implement cũng một chín một mười với nhau.
3.1. Chuẩn bị dữ liệu
Dữ liệu cần để đưa vào cho model AutoRec là bộ các vector rating (phần này chúng ta sẽ thực nghiệm theo Item-based, nên vector $r$ sẽ được ngầm hiểu là $r^{(i)}$), vì thế ta sẽ cần thiết kế một cách nào đó truyền dạng dữ liệu này vào sao cho tiện lợi nhất.
Thường trong các bài toán CF, ta sẽ cần một ma trận user-item (user-item matrix) mà các phần tử của ma trận này là rating của user dành cho item ở vị trí tương ứng. Để tạo được từ bộ dữ liệu Movielens ở trên, ta sẽ tạo một ma trận user-item rỗng, rồi đọc từng dòng rating của file ratings.dat để điền vào ma trận vừa tạo này.
Đây là một số thư viện cần import trước
1
2
3
4
5
6
7
8
9
10
import torch
import time
import pandas as pd
from torch import nn, div, square, norm
from torch.nn import functional as F
from torchdata import datapipes as dp
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
Khai báo một số biến cần sử dụng
1
2
3
datapath = 'ml-1m/'
seed = 12
device = 'cuda' if torch.cuda.is_available() else 'cpu'
Ta cần biết số lượng user, số lượng item nên phải đọc dữ liệu từ hai file users.dat và movies.dat để lấy thông tin.
1
2
3
4
5
6
7
8
9
10
11
num_users = pd.read_csv(datapath + 'users.dat',
delimiter='::',
engine='python',
encoding='latin-1',
header=None)[0].max()
num_items = pd.read_csv(datapath + 'movies.dat',
delimiter='::',
engine='python',
encoding='latin-1',
header=None)[0].max()
num_users, num_items
Kết quả là có $6040$ user và $3952$ item.
1
(6040, 3952)
Thường trong các hệ thống khuyến nghị, người ta sẽ sử dụng một tập các item (hoặc user) cho mục đích huấn luyện và một tập riêng biệt item (hoặc user) khác cho mục đích kiểm thử. Ở đây chúng ta cũng sẽ làm như vậy, ta biết item sẽ có id từ $1$ đến num_items, nên ta sẽ generate một sequence từ $0 \rightarrow \text{num_items}$ và chia ra $80\%$ cho huấn luyện, $20\%$ cho kiểm thử.
1
2
3
4
train_items, test_items = train_test_split(torch.arange(num_items),
test_size=0.2,
random_state=seed)
train_items.size(), test_items.size()
1
(torch.Size([3161]), torch.Size([791]))
Sau đó chúng ta tạo một ma trận user-item rỗng toàn cục
1
user_item_mat = torch.zeros((num_users, num_items))
Rồi đọc các dòng của file ratings.dat rồi điền vào ma trận rỗng trên
1
2
3
4
5
6
7
8
9
10
11
12
13
ratings = pd.read_csv(datapath + 'ratings.dat',
encoding='latin-1',
header=None,
engine='python',
delimiter='::')
def create_data_from_line(line):
user_id, item_id, rating, *_ = line
user_item_mat[user_id - 1, item_id - 1] = rating
return None
# dùng hàm đặc biệt của pandas để code ngắn gọn hơn
ratings.T.apply(create_data_from_line)
Sau khi điền, ta sẽ thấy được tỉ lệ rỗng của ma trận này rất cao, $\approx 96\%$
1
torch.where(user_item_mat == 0, 1, 0).sum() / (num_users * num_items)
1
tensor(0.9581)
Do model được code trên PyTorch, nên ta sẽ cần một cách để đưa dữ liệu vào model. Ta có thể dùng Dataset rồi truyền dữ liệu vào DataLoader theo batch, hoặc cũng có thể tạo một DataPipes, chia batch và truyền vào DataLoader, trong phần này tôi sử dụng DataPipes (bạn đọc có thể tìm hiểu thêm ở đây).
Tạo một hàm để tạo DataPipes từ một mảng (mảng này được lấy từ phần chia train-test ở trên) và một hàm để gom tất cả các phần tử của batch lại thành một Long Tensor.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def collate_fn(batch):
return torch.LongTensor(batch)
def create_datapipe_from_array(array, mode='train', batch_size=32, len=1000):
pipes = dp.iter.IterableWrapper(array)
pipes = pipes.shuffle(buffer_size=len)
pipes = pipes.sharding_filter()
if mode == 'train':
pipes = pipes.batch(batch_size, drop_last=True)
else:
pipes = pipes.batch(batch_size)
pipes = pipes.map(collate_fn)
return pipes
Tạo hai DataPipes train và test từ hàm ở trên
1
2
3
4
batch_size = 512
train_dp = create_datapipe_from_array(train_items, batch_size=batch_size)
test_dp = create_datapipe_from_array(test_items, mode='test', batch_size=batch_size)
Rồi tạo hai DataLoader từ hai DataPipes ở trên
1
2
3
4
num_workers = 2
train_dl = DataLoader(dataset=train_dp, shuffle=True, num_workers=num_workers)
test_dl = DataLoader(dataset=test_dp, shuffle=False, num_workers=num_workers)
Chỉ cần hai DataLoader này là chúng ta đã có dữ liệu sẵn sàng cho việc thực nghiệm
3.2. Thiết kế mô hình AutoRec
Ta có thể sử dụng AutoRec theo 2 kiểu, tôi sẽ gọi là kiểu công thức và kiểu deep learning từ bây giờ để bạn đọc tiện theo dõi.
Nếu theo kiểu công thức, ta sẽ code như thế này
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class AutoRec(nn.Module):
def __init__(self, d, k, lambda_):
super().__init__()
self.lambda_ = lambda_
self.W = nn.Parameter(torch.randn(d, k))
self.V = nn.Parameter(torch.randn(k, d))
self.mu = nn.Parameter(torch.randn(k))
self.b = nn.Parameter(torch.randn(d))
def regularization(self):
return div(self.lambda_, 2) * (square(norm(self.W)) + square(norm(self.V)))
def forward(self, r):
encoder = self.V.matmul(r.T).T + self.mu
return self.W.matmul(encoder.sigmoid().T).T + self.b
Còn nếu theo kiểu deep learning, ta sẽ code như thế này
1
2
3
4
5
6
7
8
9
10
11
12
class AutoRec(nn.Module):
def __init__(self, d, k, dropout):
super().__init__()
self.seq = nn.Sequential(
nn.Linear(d, k),
nn.Sigmoid(),
nn.Dropout(dropout),
nn.Linear(k, d)
)
def forward(self, r):
return self.seq(r)
Ở đây ta thấy là kiểu deep learning sẽ thay phần regularization phía trên thành dropout. Tiếp theo, ta cần định nghĩa hàm train và hàm eval, hai hàm này của hai cách implement chỉ khác nhau ở phần tính loss.
Kiểu theo công thức
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
def train_epoch(model, dl, opt, criterion):
list_loss = []
start_time = time.perf_counter()
for batch_idx, items_idx in enumerate(dl):
r = user_item_mat[:, items_idx].squeeze().permute(1, 0).to(device)
r_hat = model(r)
loss = criterion(r, r_hat * torch.sign(r)) + model.regularization()
list_loss.append(loss.item())
if batch_idx % 50 == 0:
log_time = round(time.perf_counter() - start_time, 4)
print("Loss {:.2f} | {:.4f}s".format(loss.item(), log_time))
opt.zero_grad()
loss.backward()
opt.step()
return list_loss
def eval_epoch(model, dl, criterion):
model.eval()
truth = []
predict = []
list_loss = []
start_time = time.perf_counter()
with torch.no_grad():
for batch_idx, items_idx in enumerate(dl):
r = user_item_mat[:, items_idx].squeeze().permute(1, 0).to(device)
r_hat = model(r)
truth.append(r)
predict.append(r_hat * torch.sign(r))
loss = criterion(r, r_hat * torch.sign(r)) + model.regularization()
list_loss.append(loss.item())
if batch_idx % 30 == 0:
log_time = round(time.perf_counter() - start_time, 4)
print("Loss {:.2f} | {:.4f}s".format(loss.item(), log_time))
rmse = torch.Tensor([torch.sqrt(square(r - r_hat).sum() / torch.sign(r).sum())
for r, r_hat in zip(truth, predict)]).mean().item()
return list_loss, rmse
Kiểu deep learning
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
def train_epoch(model, dl, opt, criterion):
list_loss = []
start_time = time.perf_counter()
for batch_idx, items_idx in enumerate(dl):
r = user_item_mat[:, items_idx].squeeze().permute(1, 0).to(device)
r_hat = model(r)
loss = criterion(r, r_hat * torch.sign(r))
list_loss.append(loss.item())
if batch_idx % 50 == 0:
log_time = round(time.perf_counter() - start_time, 4)
print("Loss {:.2f} | {:.4f}s".format(loss.item(), log_time))
opt.zero_grad()
loss.backward()
opt.step()
return list_loss
def eval_epoch(model, dl, criterion):
model.eval()
truth = []
predict = []
list_loss = []
start_time = time.perf_counter()
with torch.no_grad():
for batch_idx, items_idx in enumerate(dl):
r = user_item_mat[:, items_idx].squeeze().permute(1, 0).to(device)
r_hat = model(r)
truth.append(r)
predict.append(r_hat * torch.sign(r))
loss = criterion(r, r_hat * torch.sign(r))
list_loss.append(loss.item())
if batch_idx % 30 == 0:
log_time = round(time.perf_counter() - start_time, 4)
print("Loss {:.2f} | {:.4f}s".format(loss.item(), log_time))
rmse = torch.Tensor([torch.sqrt(square(r - r_hat).sum() / torch.sign(r).sum())
for r, r_hat in zip(truth, predict)]).mean().item()
return list_loss, rmse
Định nghĩa model, optimizer và loss function
Kiểu theo công thức
1
2
3
model = AutoRec(d=num_users, k=500, lambda_=0.0001).to(device)
opt = torch.optim.Adam(model.parameters(), lr=0.012, weight_decay=1e-5)
criterion = nn.MSELoss().to(device)
Kiểu deep learning
1
2
3
model = AutoRec(d=num_users, k=500, dropout=0.1).to(device)
opt = torch.optim.Adam(model.parameters(), lr=0.0001, weight_decay=1e-5)
criterion = nn.MSELoss()
Cụ thể hơn về code, bạn đọc có thể tham khảo ở Github respository này.
Kết quả sau khi thực nghiệm, ta có bảng dưới đây
| Kiểu implementation | Test Loss | RMSE |
|---|---|---|
| Formula style | $0.06$ | $\approx 0.932$ |
| Deep learning style | $0.04$ | $\approx 0.947$ |
Kết quả của tác giả trình bày trong paper gốc trên bộ dữ liệu Movielens 1M có RMSE là $0.831$.
4. Tổng kết
Trong bài viết này, tôi đã đi qua sơ lược về hệ thống khuyến nghị và phương pháp lọc cộng tác, từ đó đi qua kiến trúc mô hình AutoRec, một dạng cải tiến của Autoencoder dành cho lọc cộng tác. Qua thực nghiệm, kết quả của cả hai dạng implementation có kết quả không quá chênh lệch nhau. Bạn đọc có thể đọc thêm về paper gốc của tác giả trong phần 5.
5. Tham khảo
[1] AutoRec: Autoencoders Meet Collaborative Filtering https://doi.org/10.48550/arXiv.2007.07224.