
Nội dung
- 1. Bài toán Audio Classification
- 2. Thực nghiệm bài toán Audio Classification với bộ dữ liệu Speech Commands
- 3. Tổng kết
- 4. Tham khảo
1. Bài toán Audio Classification
Bài toán nhận diện âm thanh là một dạng bài toán phổ thông và có nhiều ứng dụng trong thực tế. Nhiệm vụ của chúng ta trong bài toán này là phân loại được các bản ghi âm thanh thành các thể loại (lớp) đã được quy định sẵn.
Đây là một bài toán phân loại bình thường, nhưng cấu trúc dữ liệu âm thanh có thể khác so với dạng ma trận có sẵn khi chúng ta làm phân lớp với mô hình Decision Tree hay Logistic Regression.
Hình dưới đây mô tả dạng tín hiệu âm thanh khi được đọc lên từ file.
 Hình 1: Dạng tín hiệu sóng của một file âm thanh.
Hình 1: Dạng tín hiệu sóng của một file âm thanh.
Ta thấy dạng sóng này có dạng 1D, vậy nên ta có thể sử dụng Convolution 1D để trích xuất thông tin từ tín hiệu. Dạng mô hình M5 là một ví dụ trong trường hợp này [1].
Nhưng thay vì xử lý trên dạng tín hiệu sóng thô của âm thanh, ta có thể trích xuất thông tin và chuyển tín hiệu âm thanh thành dạng ảnh để xử lý trên kiến trúc CNN 2D, tiện lợi hơn, đơn giản hơn và phổ biến hơn. Hình dưới đây mô tả dạng Mel Spectrogram sau khi chuyển từ dạng tín hiệu sóng. Ta thấy nó giống hệt một tấm ảnh.
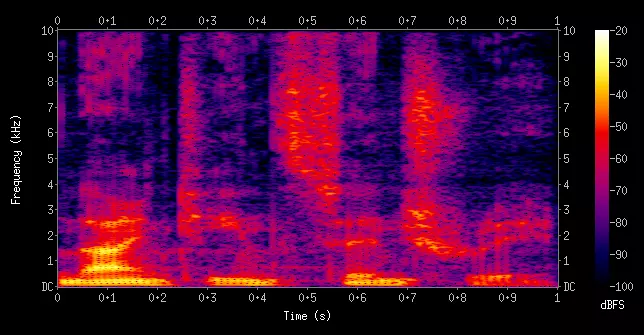 Hình 2: Dạng Mel Spectrogram của một file âm thanh.
Hình 2: Dạng Mel Spectrogram của một file âm thanh.
Các bước thực hiện bài toán nhận dạng âm thanh:
- Chuyển dữ liệu tín hiệu âm thanh thành dạng Mel Spectrogram.
- Sử dụng một kiến trúc CNN cho bài toán phân loại để học Mel Spectrogram được chuyển từ các file.
- Đánh giá mô hình.
Ta có thể sử dụng bất kì kiến trúc CNN xử lý trên ảnh 2D nào cho bài toán này. Ở đây mình sẽ sử dụng kiến trúc AlexNet [2] cho đơn giản. Hình dưới mô tả AlexNet cho bài toán này, nhận vào một Mel Spectrogram và xuất ra phân bố xác suất với kích cỡ là số lượng lớp của dữ liệu.
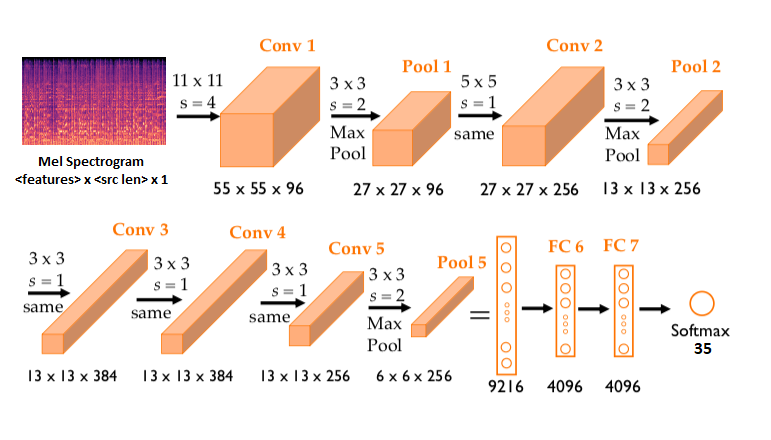 Hình 3: Kiến trúc AlexNet trong bài toán này.
Hình 3: Kiến trúc AlexNet trong bài toán này.
2. Thực nghiệm bài toán Audio Classification với bộ dữ liệu Speech Commands
2.1. Bộ dữ liệu Speech Commands
Bộ dữ liệu này chứa 35 lớp, với mỗi lớp là tập hợp những file âm thanh ghi âm giọng nói của người nói từ vựng của lớp đó. Các lớp bao gồm những từ vựng dưới đây:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
labels = [
"house",
"marvin",
"yes",
"bird",
"no",
"on",
"off",
"wow",
"backward",
"happy",
"nine",
"forward",
"left",
"one",
"visual",
"up",
"learn",
"five",
"bed",
"stop",
"dog",
"tree",
"right",
"three",
"zero",
"six",
"two",
"go",
"sheila",
"down",
"seven",
"follow",
"eight",
"cat",
"four",
]
Ta sẽ sử dụng bộ dữ liệu này từ thư viện torchaudio cho tiện, không mất công quản lý file.
2.2. Những thành phần cần thiết của Pytorch Lightning cho bài toán
Đối với Pytorch thông thường, ta sẽ phải chuẩn bị dữ liệu thông qua Dataset, chia batch dữ liệu thông qua DataLoader, chuẩn bị mô hình, chuẩn bị hàm train và hàm validate, lưu lại các thông tin lúc train… . Có quá nhiều thông tin cần quản lý. Thay vào đó, bài viết này mình sẽ thực hiện bằng Pytorch Lightning để tiện quản lý các thành phần. Bạn đọc có thể tìm hiểu kỹ hơn về Pytorch Lightning ở đây.
Trước mắt, ta sẽ cần:
DataModule: Module quản lý dữ liệu âm thanh theo batch.ModelModule: Module quản lý model, optimizer, scheduler và thao tác thực hiện của hàm train, validate và test.
Dưới đây là code của Data Module được đặt trong file datamodule.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
import torch
from utils import labels2int
import pytorch_lightning as pl
import torchaudio.transforms as T
from torch.utils.data import DataLoader
from torchaudio.datasets import SPEECHCOMMANDS
from torch.nn.utils.rnn import pad_sequence
class SpeechCommandDataModule(pl.LightningDataModule):
def __init__(
self,
root: str = "./",
batch_size: int = 64,
n_fft: int = 200,
pin_memory=False,
):
super().__init__()
# thư mục lưu dữ liệu
self.root = root
self.batch_size = batch_size
# tạo class MelSpectrogram với số lượng fast fourier transform được chỉ định sẵn
self.transform = T.MelSpectrogram(n_fft)
self.pin_memory = pin_memory
def prepare_data(self):
'''
Hàm này để chuẩn bị dữ liệu, tải dữ liệu sẽ được tự gọi khi khởi tạo
'''
SPEECHCOMMANDS(self.root, download=True)
def setup(self, stage):
'''
Hàm này chuẩn bị dữ liệu train, test, val
'''
self.train_set = SPEECHCOMMANDS(self.root, subset="training")
self.test_set = SPEECHCOMMANDS(self.root, subset="testing")
self.val_set = SPEECHCOMMANDS(self.root, subset="validation")
def train_dataloader(self):
'''
DataLoader của hàm train
'''
return DataLoader(
self.train_set,
batch_size=self.batch_size,
collate_fn=self.__collate_fn,
pin_memory=self.pin_memory,
shuffle=True, # shuffle dữ liệu để tạo sự đa dạng
)
def val_dataloader(self):
'''
DataLoader của hàm validate
'''
return DataLoader(
self.val_set,
batch_size=self.batch_size,
collate_fn=self.__collate_fn,
pin_memory=self.pin_memory,
)
def test_dataloader(self):
'''
DataLoader của hàm test
'''
return DataLoader(
self.test_set,
batch_size=self.batch_size,
collate_fn=self.__collate_fn,
pin_memory=self.pin_memory,
)
def __collate_fn(self, batch):
'''
Hàm này sẽ nhận vào một batch và
chuyển các dữ liệu âm thanh thành dạng Mel Spectrogram
pad thêm số 0 vào để kích cỡ bằng nhau
phục vụ cho việc nhân ma trận của mô hình.
'''
mel_specs = [self.transform(i[0]).squeeze().permute(1, 0) for i in batch]
labels = torch.LongTensor([labels2int.get(i[2]) for i in batch])
mel_specs = pad_sequence(mel_specs, batch_first=True)
# thêm 3 channel
# do mô hình alexnet yêu cầu đầu vào là một ảnh có 3 channel
# nên ta sẽ xếp chồng 3 lần tấm ảnh mel spectrogram lên để có 3 channel
mel_specs = torch.stack([mel_specs, mel_specs, mel_specs], dim=1)
return mel_specs, labels
Dưới đây là code Model Module của file model.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
import torch
from torch import nn
import pytorch_lightning as pl
from torchvision.models.alexnet import AlexNet
class ModelModule(pl.LightningModule):
def __init__(
self,
num_classes: int = 10,
dropout: float = 0.5,
lr: float = 0.01,
optim_configs: dict = {}
):
super().__init__()
self.alexnet = AlexNet(num_classes=num_classes, dropout=dropout)
self.lr = lr
self.optim_configs = optim_configs
def forward(self, x: torch.Tensor):
'''hàm này để dự đoán'''
output = self.alexnet(x)
return output.argmax(dim=-1)
def configure_optimizers(self):
# dùng adam optimizer
optimizer = torch.optim.Adam(
self.parameters(), lr=self.lr, **self.optim_configs
)
return optimizer
def training_step(self, batch, batch_idx):
'''
Hàm này nhận vào một batch
lấy kết quả của mô hình và tính loss
mô hình sẽ tự tính back propagation
'''
x, y = batch
out = self.alexnet(x)
loss = nn.functional.cross_entropy(out, y)
# lưu lại loss của train
self.log("train_loss", loss.item())
self.log("lr", self.lr)
return loss
def validation_step(self, batch, batch_idx):
'''
Hàm này nhận vào một batch
lấy kết quả của mô hình và tính loss
'''
x, y = batch
out = self.alexnet(x)
loss = nn.functional.cross_entropy(out, y)
# lựa chọn lớp có xác suất cao nhất để làm dự đoán
pred = out.argmax(dim=-1)
# tính accuracy
acc = (pred == y).sum() / y.size(0)
# lưu lại loss của validate
self.log("val_loss", loss.item())
self.log("val_acc", acc.item())
return loss, acc
def test_step(self, batch, batch_idx):
x, y = batch
out = self.alexnet(x)
loss = nn.functional.cross_entropy(out, y)
# lựa chọn lớp có xác suất cao nhất để làm dự đoán
pred = out.argmax(dim=-1)
# tính accuracy
acc = (pred == y).sum() / y.size(0)
# lưu lại loss của test
self.log("test_loss", loss.item())
self.log("test_acc", acc.item())
return loss, acc
Ta thấy các thao tác như train, test, validate, chuẩn bị dataloader, optimizer, scheduler, lưu lại loss, lưu lại accuracy được quản lý bởi hai lớp SpeechCommandDataModule và ModelModule, gọn hơn nhiều so với việc quản lý từng thành phần riêng lẻ.
Do label của chúng ta là chữ, nên ta sẽ quản lý lại thành các số, từ đó tiện cho mô hình tính toán loss.
File utils.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# số sang label chữ
labels = [
"house",
"marvin",
"yes",
"bird",
"no",
"on",
"off",
"wow",
"backward",
"happy",
"nine",
"forward",
"left",
"one",
"visual",
"up",
"learn",
"five",
"bed",
"stop",
"dog",
"tree",
"right",
"three",
"zero",
"six",
"two",
"go",
"sheila",
"down",
"seven",
"follow",
"eight",
"cat",
"four",
]
# label chữ sang số
labels2int = dict(zip(labels, range(len(labels))))
Cuối cùng, ta tập hợp tất cả lại để trong file main.py.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import hydra
import argparse
from omegaconf import OmegaConf, DictConfig
from datamodule import SpeechCommandDataModule
from model import ModelModule
import pytorch_lightning as pl
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Config path")
parser.add_argument("-cp", help="config path") # config path
parser.add_argument("-cn", help="config name") # config name
args = parser.parse_args()
@hydra.main(config_path=args.cp, config_name=args.cn)
def main(cfg: DictConfig):
dm = SpeechCommandDataModule(**cfg.datamodule)
model = ModelModule(**cfg.model)
logger = pl.loggers.tensorboard.TensorBoardLogger(**cfg.logger)
trainer = pl.Trainer(logger=logger, **cfg.trainer)
trainer.fit(model, datamodule=dm)
trainer.test(model, datamodule=dm)
main()
Ở đây, mình sử dụng một thư viện tên là hydra để quản lý các tinh chỉnh của tất cả thành phần trong code, như vậy khi huấn luyện sẽ không cần sửa code mà chỉ cần tinh chỉnh file configs là được.
Đây là file configs mẫu của mình. Bạn đọc có thể tinh chỉnh lại cho phù hợp với mỗi máy cá nhân.
datamodule:
root: /kaggle/working/ # thư mục gốc để chứa dữ liệu sẽ được tải về
batch_size: 128 # batch size của dataloader
n_fft: 200 # số lượng fourier transform
pin_memory: True # True if gpu
model:
num_classes: 35 # số lượng lớp của dữ liệu
dropout: 0.1 # tỉ lệ dropout
lr: 0.001 # learning rate khởi tạo
optim_configs:
weight_decay: 0.0001
logger:
save_dir: tb_logs # thư mục lưu log của tensorboard
name: alexnet_logs # tên của log
trainer:
max_epochs: 10 # số epoch tối đa
accelerator: auto # có thể là cpu, gpu, tpu. Auto sẽ tự lựa chọn dựa trên môi trường.
Bạn đọc có thể huấn luyện mô hình trên máy cá nhân hoặc Colab, đối với mình, mình sẽ huấn luyện trên Kaggle. Đây là link Kaggle mình sử dụng để config và train model này, bạn đọc có thể tham khảo Kaggle.
2.3. Kết quả
Do Pytorch Lightning lưu kết quả để tiện theo dõi trong Tensorboard, nên ta có thể theo dõi thông qua nó.
Dưới đây là thông tin loss của tập dữ liệu train. Ta thấy loss giảm rất nhanh trong 1000, 2000 step đầu tiên, sau đó có thể learning rate vẫn hơi cao nên giao động loss xảy ra. Có lẽ chúng ta nên thêm một Learning Rate Scheduler vào mô hình, bạn đọc có thể thử nghiệm xem kết quả như thế nào. Nhưng tổng quan hình 4 thì ta thấy loss giảm, chứng tỏ mô hình đang học đúng hướng.
 Hình 4: Loss theo thời gian của mô hình trên tập dữ liệu train.
Hình 4: Loss theo thời gian của mô hình trên tập dữ liệu train.
Dưới đây là thông tin loss của tập dữ liệu validate. Loss của tập validate cũng giảm nên ta cũng ngầm hiểu mô hình đang học đúng.
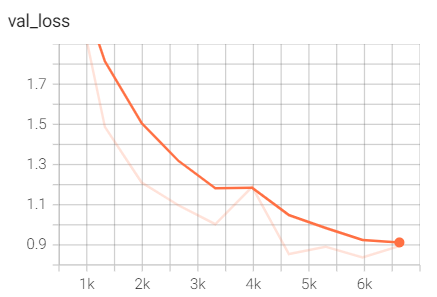 Hình 5: Loss theo thời gian của mô hình trong quá trình validate.
Hình 5: Loss theo thời gian của mô hình trong quá trình validate.
Độ chính xác của tập dữ liệu validate. Ở đây, ta thấy độ chính xác (accuracy) tăng theo thời gian, chứng tỏ mô hình càng ngày càng cải thiện và mô hình học được tốt. Độ chính xác và loss cuối cùng của tập validate được thể hiện ở hình 7.
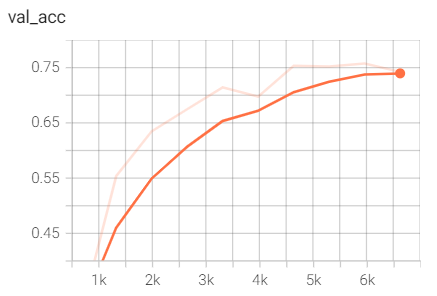 Hình 6: Độ chính xác theo thời gian của mô hình trong quá trình validate
Hình 6: Độ chính xác theo thời gian của mô hình trong quá trình validate
 Hình 7: Độ chính xác và loss cuối cùng của tập validate
Hình 7: Độ chính xác và loss cuối cùng của tập validate
3. Tổng kết
Bài viết này đã đi qua về định nghĩa bài toán nhận diện âm thanh và thực nghiệm trên bộ dữ liệu Speech Commands với mô hình AlexNet. Chúng ta thấy độ chính xác cuối cùng vào khoảng $73%$, không quá cao nhưng thể hiện được mô hình này có thể hoạt động tốt. Bạn đọc có thể thêm Learning Rate Scheduler, tinh chỉnh Optimizer, điều chỉnh learning rate, train thêm nhiều epoch và chỉnh sửa các thông tin khác để mô hình hoạt động tốt hơn.
Bạn đọc có thể tham khảo thêm về:
- Tổng hợp code của bài toán: Audio Classification - Github.
- Code thực nghiệm mô hình: Speech Commands Audio Classification - Kaggle.
4. Tham khảo
[1] Very Deep Convolutional Neural Networks For Raw Waveforms https://arxiv.org/pdf/1610.00087.pdf.
[2] ImageNet classification with deep convolutional neural networks https://dl.acm.org/doi/10.1145/3065386.