
Nội dung
- 1. Giới thiệu Autoencoder
- 2. Bài toán phát hiện bất thường trong an ninh mạng
- 3. Thực nghiệm Autoencoder với bộ dữ liệu NSL-KDD
- 4. Tổng kết
- 5. Tham khảo
1. Giới thiệu Autoencoder
Autoencoder là một mạng neuron truyền thẳng học không giám sát (unsupervised feedforward neural network). Mục đích của Autoencoder là cố gắng tái tạo dữ liệu đầu vào sao cho giống nhất có thể. Autoencoder thường được dùng trong các bài toán giảm chiều dữ liệu, khử nhiễu từ ảnh hoặc phát hiện bất thường, trong bài viết này, chúng ta sẽ tập trung vào bài toán phát hiện bất thường.
 Hình 1: Cấu trúc cơ bản của Autoencoder
Hình 1: Cấu trúc cơ bản của Autoencoder
Một mạng Autoencoder có thể chia thành 3 thành phần chính: encoder $f(x)$, code $h$ và decoder $g(h)$. Cụ thể thì mạng sẽ trông như hình 1. Lớp code còn được gọi là lớp đại diện, thường thì sẽ có kích cỡ nhỏ nhất trong mạng, tác dụng chính của lớp này dùng để lưu trữ những thông tin quan trọng nhất từ dữ liệu đầu vào. Trong khi đó, lớp encoder cố gắng đưa dữ liệu đầu vào thành lớp code, còn lớp decoder cố gắng tái tạo lại dữ liệu đầu ra từ lớp code. Nếu coi $x$ là dữ liệu đầu vào, $r$ là dữ liệu tái tạo từ lớp decoder, ta có thể hiểu là: $h=f(x)$, $r=g(h)$. Autoencoder thực chất cũng là mạng neuron, nên có thể huấn luyện thông qua back-propagation với hàm lỗi là $L(x, r)$, thường thì hàm lỗi sẽ là Mean Square Error.
Cấu trúc của encoder, code và decoder trong mỗi dạng, bài toán sử dụng Autoencoder sẽ khác nhau. Một mạng Autoencoder đơn giản sẽ chỉ có 3 lớp ẩn, tương ứng với 3 lớp encoder, code và decoder, trong đó encoder và decoder có kích cỡ giống nhau, code sẽ có kích cỡ nhỏ. Còn một mạng Deep Autoencoder sẽ xếp chồng nhiều lớp ẩn lại và thu nhỏ kích cỡ lần lượt trong encoder, decoder sẽ là phiên bản ngược lại của encoder. Hình 2 mô tả cấu trúc của mạng Deep Autoencoder. Deep Autoencoder đặc biệt thích hợp trong bài toán phát hiện bất thường.
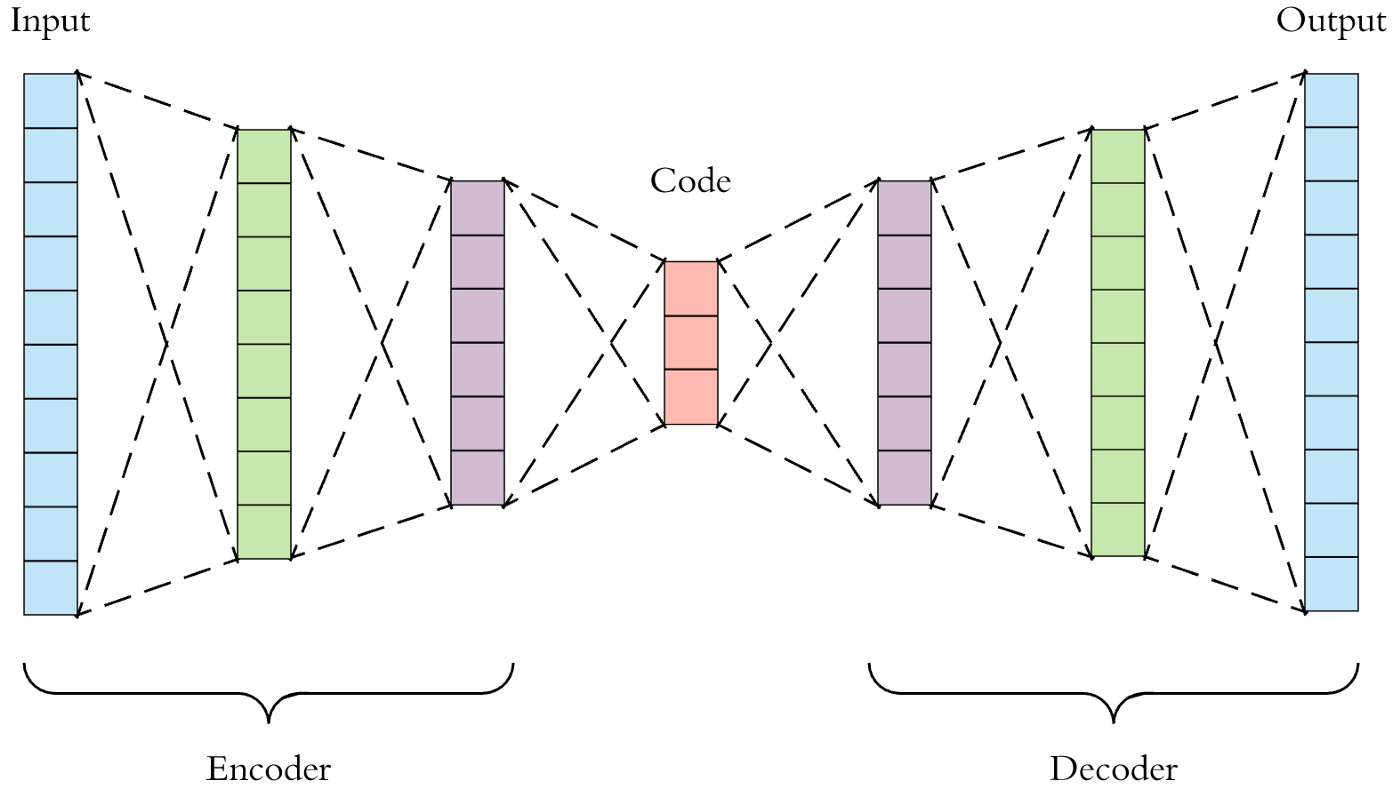 Hình 2: Cấu trúc của Deep Autoencoder
Hình 2: Cấu trúc của Deep Autoencoder
2. Bài toán phát hiện bất thường trong an ninh mạng
Bất thường, tiếng anh là anomaly, outliers là những dữ liệu trông có vẻ khác xa so với đa số dữ liệu chúng ta có. Có thể là một điểm có giá trị rất lớn trong tập dữ liệu mà đa phần chỉ toàn giá trị nhỏ.
Trong lĩnh vực an ninh mạng, dữ liệu sẽ là những thông tin trong mạng, như thời gian gửi gói tin, độ trễ, thời gian chờ,… . Đa phần người sử dụng mạng trong một mạng lưới là người dùng bình thường, không có mục đích tấn công vào một trụ sở, nên dữ liệu của mỗi người sẽ tương đối giống nhau. Nhưng đối với những người dùng có ý đồ xấu, gọi là hacker, dữ liệu mạng này sẽ khác so với dữ liệu của một người dùng bình thường, nguyên nhân là các hacker sẽ dùng các phương pháp tấn công đặc biệt, mà trong quá trình thao tác, dữ liệu mạng sẽ bị biến đổi theo cách khác. Ta có thể dựa vào đó để phát hiện xâm nhập trong an ninh mạng.
Mục đích của Autoencoder sẽ là cố gắng tái tạo dữ liệu đầu vào sao cho giống nhất với dữ liệu huấn luyện. Dựa vào thông tin này, ta có thể chỉ đưa dữ liệu thuộc lớp normal là dữ liệu bình thường, không phải bất thường cho Autoencoder học. Sau đó ta sẽ đi tính lỗi tái tạo (reconstruction error) trên cả tập dữ liệu normal lẫn abnormal, nếu độ lỗi tái tạo càng nhỏ, có nghĩa là việc Autoencoder tái tạo tập normal là đúng, ngược lại, độ lỗi tái tạo cao, nghĩa là dữ liệu đầu vào khác so với normal, nghĩa là abnormal, lúc này độ lỗi tái tạo giống như một histogram, ta chỉ cần tìm một ngưỡng để phân tách hai tập lỗi của normal và abnormal. Bài toán lúc này trở thành bài toán phân loại nhị phân (binary classification).
3. Thực nghiệm Autoencoder với bộ dữ liệu NSL-KDD
3.1 Giới thiệu bộ dữ liệu NSL-KDD
Bộ dữ liệu NSL-KDD khá nổi tiếng, được cải thiện từ bộ dữ liệu KDD’99. Dữ liệu này là về những thông tin mạng được thu thập bởi các nhà nghiên cứu, dữ liệu được chia thành nhiều nhãn, nhãn normal là thông tin gói tin bình thường từ người dùng bình thường và các nhãn khác như của các phương thức tấn công như neptune, warezclient, ipsweep, portsweep, v.v là của những người dùng có ý đồ xấu, gọi là hacker. Nhưng chúng ta sẽ coi tất cả phương thức tấn công như nhãn abnormal cho gọn. Bạn đọc có thể xem thêm chi tiết về bộ dữ liệu ở đây
3.2 Hiện thực
Bài toán sẽ được hiện thực bằng ngôn ngữ lập trình Python, kết hợp thêm thư viện Tensorflow để xây dựng mô hình Autoencoder.
Trước tiên ta sẽ đọc dữ liệu lên, bao gồm cả dữ liệu huấn luyện từ KDDTrain+.txt và dữ liệu kiểm thử KDDTest+.txt, đây là hai tập dữ liệu đầy đủ nhất, các tập dữ liệu còn lại được trích ra từ hai tập này.
Các thư viện được sử dụng trong hiện thực:
1
2
3
4
5
6
7
8
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.preprocessing import OneHotEncoder, MinMaxScaler
Đọc dữ liệu lên bằng pandas.
1
2
train = pd.read_csv('NSL-KDD-Dataset/KDDTrain+.txt', header=None)
test = pd.read_csv('NSL-KDD-Dataset/KDDTest+.txt', header=None)
Nói sơ qua về tập dữ liệu thì chúng ta có 43 cột, bao gồm các kiểu dữ liệu số và chữ. Cột dữ liệu cuối cùng là cột difficulty, theo link ở trên phần 3.1, nó không có tác dụng mấy trong việc xác định bất thường, nên ta sẽ bỏ đi. Cột dữ liệu kế cuối, có chỉ số là 41 là cột label của dữ liệu, bao gồm normal và các phương thức tấn công khác, mà ta lại muốn chuyển các phương thức tấn công thành abnormal, nên cuối cùng cột này sẽ chỉ có 2 giá trị duy nhất: normal và abnormal. Ngoài ra các cột dữ liệu chữ khác cũng cần được chuyển sang dạng OneHot, nghĩa là các giá trị chữ sẽ được chuyển thành một vector có độ dài bằng số lượng giá trị chữ duy nhất, sẽ điền giá trị 1 vào nếu phần tử tương ứng xuất hiện, ngược lại là 0, bạn đọc có thể tìm hiểu về OneHot ở đây. Các cột dữ liệu số không có khoảng giống nhau, như thế sẽ khiến cho mô hình hội tụ chậm hơn, nên ta cũng cần scale về $[0, 1]$ để tiện cho hàm activation sigmoid được sử dụng trong mô hình Autoencoder về sau.
Ta sẽ định nghĩa hai lớp dùng cho việc mã hóa OneHot và scale dữ liệu:
1
2
encoder = OneHotEncoder(handle_unknown='ignore')
scaler = MinMaxScaler()
Và định nghĩa một hàm để xử lý dữ liệu, dùng cho cả tập huấn luyện và kiểm thử đọc ở trên.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
def preprocess(df, is_fit=True):
# chuyển normal thành 1 và các lớp khác thành 0
label = np.where(df[41] == 'normal', 'normal', 'abnormal')
# loại bỏ cột dữ liệu không cần thiết
df.drop([41, 42], axis=1)
# chia dữ liệu ra số, chữ để tiện xử lý
numerical_data = df.select_dtypes(exclude='object').values
categorical_data = df.select_dtypes(include='object').values
# chỉ fit với dữ liệu train
if is_fit:
encoder.fit(categorical_data)
# chuyển từ dữ liệu chữ sang onehot
categorical_data = encoder.transform(categorical_data).toarray()
# nối dữ liệu số và onehot lại
data = np.concatenate([numerical_data, categorical_data], axis=1)
# chỉ fit với dữ liệu train
if is_fit:
scaler.fit(data)
# dữ liệu chuẩn hóa về dạng [0, 1]
data = scaler.transform(data)
return dict(data=data, label=label)
Sau đó đi xử lý cho hai tập. Một lưu ý nhỏ ở đây là ta cần cả hai tập huấn luyện và kiểm thử sau khi xử lý phải có số cột giống nhau, scale dữ liệu cũng sẽ giống nhau. Nên ta chỉ cần fit dữ liệu huấn luyện vào encoder và scaler, tập huấn luyện sẽ chỉ dùng lại dữ liệu đã fit, nên cả hai tập dữ liệu sẽ có số lượng cột giống nhau sau khi xử lý.
1
2
3
# xử lý dữ liệu
train = preprocess(train, True)
test = preprocess(test, False)
Dữ liệu sau khi xử lý sẽ có cùng số lượng cột.
1
train['data'].shape, test['data'].shape
((125973, 146), (22544, 146))
Tiếp theo ta sẽ định nghĩa kiến trúc của Autoencoder. Lớp encoder sẽ có các lớp lần lượt là 64 -> 32 -> 16 -> 8. Lớp decoder sẽ có kích cỡ là 16 -> 32 -> 64 -> 146. Ở đây, 8 là lớp code, là lớp nhỏ nhất, đại diện cho thông tin quan trọng nhất đã được mã hóa, 146 là kích cỡ dữ liệu đầu vào, do ta muốn kích cỡ đầu ra phải giống hệt đầu vào. Ngoài lớp cuối cùng dùng hàm kích hoạt sigmoid để tạo dữ liệu về scale $[0, 1]$, thì các lớp còn lại sẽ dùng hàm kích hoạt tanh. Dưới đây mô tả lớp Autoencoder được thiết kế. Ngoài ra, ta sẽ tạo thêm hàm get_construction_error để tính lỗi tái tạo, hàm predict_class sẽ đi dự đoán ra lớp normal hay abnormal cụ thể.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
class Autoencoder(keras.Model):
def __init__(self, input_dim):
super(Autoencoder, self).__init__()
self.encoder = keras.Sequential([
keras.layers.Dense(64, activation='tanh'),
keras.layers.Dense(32, activation='tanh'),
keras.layers.Dense(16, activation='tanh'),
keras.layers.Dense(8, activation='tanh')
])
self.decoder = keras.Sequential([
keras.layers.Dense(16, activation='tanh'),
keras.layers.Dense(32, activation='tanh'),
keras.layers.Dense(64, activation='tanh'),
keras.layers.Dense(input_dim, activation='sigmoid'),
])
def call(self, x):
code = self.encoder(x)
r = self.decoder(code)
return r
def get_reconstruction_error(self, x):
r = self.predict(x)
return keras.metrics.mean_squared_error(x, r)
def predict_class(self, x, threshold):
reconstruction_error = self.get_reconstruction_error(x)
return np.where(reconstruction_error <= threshold, 'normal', 'abnormal')
Ta sẽ đem chia các tập dữ liệu ra để tiện cho quá trình huấn luyện và kiểm thử.
1
2
3
4
5
6
# chia dữ liệu
train_normal = train['data'][train['label'] == 'normal']
train_abnormal = train['data'][train['label'] == 'abnormal']
test_normal = test['data'][test['label'] == 'normal']
test_abnormal = test['data'][test['label'] == 'abnormal']
Ta định nghĩa optimizer và loss function cho mô hình Autoencoder trên, optimizer có thể sử dụng là Adam, một dạng của Gradient-Descent, loss function có thể sử dụng là Mean Square Error, đo lường sự sai khác của dữ liệu số.
1
2
3
4
model = Autoencoder(train_normal.shape[1])
optimizer = keras.optimizers.Adam()
loss_fn = keras.losses.MeanSquaredError()
model.compile(optimizer, loss_fn)
Đem huấn luyện mô hình với batch size là 64 và số lượng lần lặp epochs là 100. Các bạn có thể dùng runtime GPU của Google Colab để tăng tốc quá trình huấn luyện.
1
model.fit(train_normal, train_normal, batch_size=64, epochs=100)
Sau khi huấn luyện, ta sẽ mong muốn tính độ lỗi tái tạo của tập dữ liệu huấn luyện và tập kiểm thử để xem phân phối lỗi như thế nào.
1
2
3
4
5
6
7
# tính độ lỗi tái tạo cho tất cả các tập dữ liệu
train_normal_re = model.get_reconstruction_error(train_normal)
train_abnormal_re = model.get_reconstruction_error(train_abnormal)
test_normal_re = model.get_reconstruction_error(test_normal)
test_abnormal_re = model.get_reconstruction_error(test_abnormal)
Ta muốn có một ngưỡng $\theta_\alpha$ sao cho có thể phân chia tốt cả hai tập lỗi này. $\alpha$ tôi chọn trong bài là $0.5$, nhưng các bạn có thể tùy chỉnh theo dữ liệu của các bạn.
1
2
3
4
# tìm ngưỡng alpha từ tập train
alpha = 0.5
threshold = np.concatenate([train_normal_re, train_abnormal_re]).mean() * alpha
print('Ngưỡng vừa tìm được từ tập train:', threshold)
Ngưỡng vừa tìm được từ tập train: 0.012324278242886066
Vẽ dữ liệu lên sẽ trông như thế này (hình 3 và 4). Độ lỗi normal bị lọt thỏm ở khoảng $0$, nghĩa là về cơ bản tái tạo giống hệt như ban đầu, còn độ lỗi abnormal khá là cao và phân phối rộng. Chỉ cần nhìn vào là ta đã biết được dữ liệu đó là thuộc lớp nào, điểm ngưỡng threshold sẽ giúp ta làm điều đó một cách chính xác hơn.
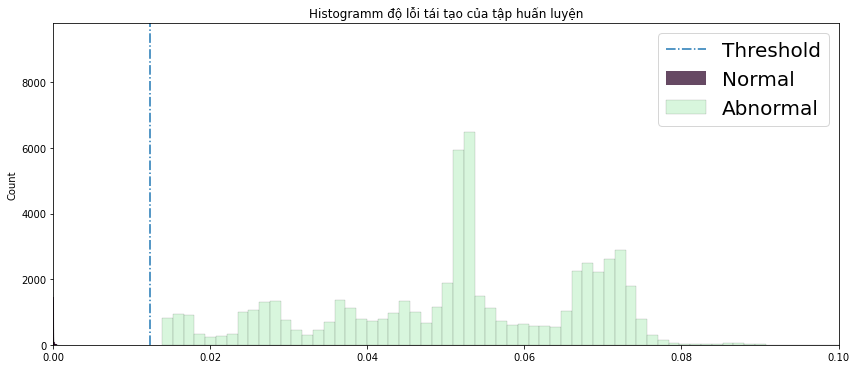 Hình 3: Histogram phân phối lỗi của tập huấn luyện
Hình 3: Histogram phân phối lỗi của tập huấn luyện
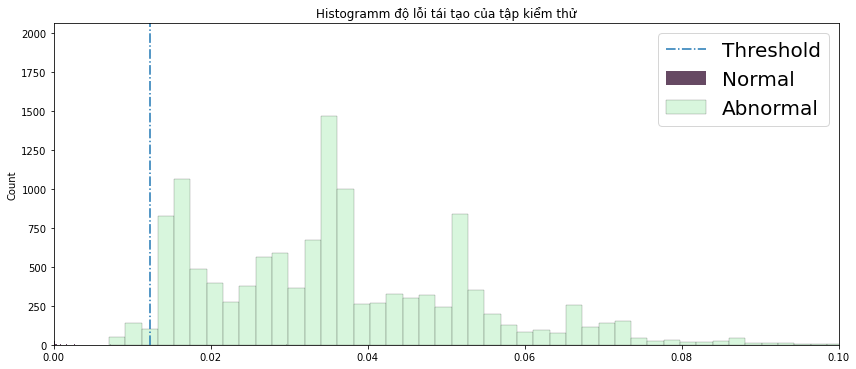 Hình 4: Histogram phân phối lỗi của tập kiểm thử
Hình 4: Histogram phân phối lỗi của tập kiểm thử
Độ chính xác trong việc phân loại hai tập dữ liệu khá cao: tập huấn luyện là 99% và tập kiểm thử là 96%.
1
2
3
train_label_predict = model.predict_class(train['data'], threshold)
print('Độ chính xác tập huấn luyện', end=': ')
accuracy_score(train['label'], train_label_predict)
Độ chính xác tập huấn luyện: 0.9978169925301453
1
2
3
test_label_predict = model.predict_class(test['data'], threshold)
print('Độ chính xác tập kiểm thử', end=': ')
accuracy_score(test['label'], test_label_predict)
Độ chính xác tập kiểm thử: 0.9633161816891412
Dưới đây là confusion matrix của hai tập dữ liệu.
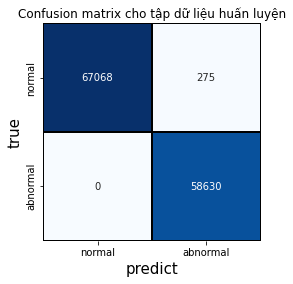 Hình 5: Confusion matrix của tập huấn luyện
Hình 5: Confusion matrix của tập huấn luyện
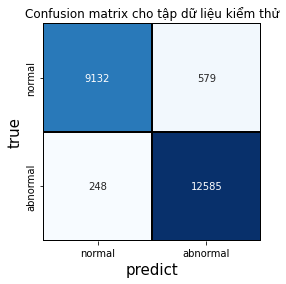 Hình 6: Confusion matrix của tập kiểm thử
Hình 6: Confusion matrix của tập kiểm thử
Toàn bộ code bạn đọc có thể lấy ở đây.
4. Tổng kết
Qua bài viết này, tôi đã giới thiệu về mô hình mạng neuron Autoencoder và ứng dụng của nó trong bài toán phát hiện bất thường trong an ninh mạng với bộ dữ liệu NSL-KDD. Kết quả sau khi thực nghiệm đạt độ chính xác cao. Bạn đọc có thể tìm hiểu thêm các dạng khác của Autoencoder như Sparse Autoencoder, Stack Autoencoder, Variational Autoencoder, v.v. Với mỗi dạng, sẽ có thể ứng dụng vào một bài toán nào đó khác nhau.
5. Tham khảo
[1] Ian Goodfellow, Yoshua Bengio, Aaron Courville. Deep Learning. 2016. MIT Press. http://www.deeplearningbook.org.
[2] Wikipedia. Autoencoder. https://en.wikipedia.org/wiki/Autoencoder.
[3] Arden Dertat. Applied Deep Learning - Part 3: Autoencoders. 03/10/2017. https://towardsdatascience.com/applied-deep-learning-part-3-autoencoders-1c083af4d798.